
Catalogues unifiés
Cette page regroupe les liens menant aux catalogues consolidés de la CFHTLS et à la documentation expliquant comment ils ont été réalisés. Vous pouvez récupérer ces catalogues sous forme de fichiers ASCII massifs ou les consulter le page Recherche des catalogues.
Introduction
Les catalogues de la CFHTLS ont été réalisés avec MegaPipe en 2008 (Champs Profonds) et au début de 2009 (Champs Larges). Ils ont été divisés par bande et pointage. Pour les produire, on a appliqué SExtractor à chaque image. Ceux qui souhaitaient se servir des catalogues devaient télécharger chacun d'eux puis les fusionner eux-mêmes.
Pour une plus grande convivialité, ces catalogues ont désormais été fusionnés. Chacun comprend donc les mesures prises avec les cinq filtres ugriz de MegaCam et englobe une étude complète (Champs Larges ou Champ profonds).
Des catalogues distincts ont été produits à partir de chacune des cinq bandes, servant d'image de référence ou de détection. Par conséquent, chaque étude comprend un catalogue pour chaque filtre u, g, r, i et z sélectionné, l'objectif scientifique de chacun étant différent. (Filtre i pour les études générales sur la population de la galaxie; filtre z pour la recherche de dropouts Lyman dans la bande i, etc.). Bien que les catalogues soient sélectionnés en fonction d'un filtre, les mesures ont été prises avec les cinq filtres pour chacun, de sorte qu'il est inutile d'en consulter plusieurs. En tout, on dénombre donc 5x2=10 catalogues distincts, chacun complet en soi, mais aux caractéristiques de détection différentes.
Catalogues
Le tableau que voici fournit quelques statistiques sur les catalogues, ainsi qu'un lien vers leur version ASCII.
| Sondage | Filtre de sélection | Nombre de lignes | Superficie (Deg2) |
Superficie masquée (Deg2) |
Catalogue complet | Catalogue concise |
|---|---|---|---|---|---|---|
| Deep | U | 990 000 | 4.02704 | 3.64042 | D.U.cat.gz (498Mb) | D.U.con.cat.gz (140Mb) |
| Deep | G | 1 600 000 | 4.02704 | 3.64042 | D.G.cat.gz (768Mb) | D.G.con.cat.gz (217Mb) |
| Deep | R | 1 600 000 | 4.02704 | 3.64042 | D.R.cat.gz (768Mb) | D.R.con.cat.gz (217Mb) |
| Deep | I | 1 600 000 | 4.02704 | 3.64042 | D.I.cat.gz (743Mb) | D.I.con.cat.gz (210Mb) |
| Deep | Z | 1 100 000 | 4.02704 | 3.64042 | D.Z.cat.gz (529Mb) | D.Z.con.cat.gz (150Mb) |
| Wide | U | 19 000 000 | 152.33481 | 148.32196 | W.U.cat.gz (8.6Gb) | W.U.con.cat.gz (2.4Gb) |
| Wide | G | 32 000 000 | 152.33481 | 146.20048 | W.G.cat.gz (15Gb) | W.G.con.cat.gz (4.1Gb) |
| Wide | R | 28 000 000 | 152.33481 | 144.69447 | W.R.cat.gz (13Gb) | W.R.con.cat.gz (3.6Gb) |
| Wide | I | 28 000 000 | 152.33481 | 144.80211 | W.I.cat.gz (13Gb) | W.I.con.cat.gz (3.6Gb) |
| Wide | Z | 19 000 000 | 152.33481 | 145.18961 | W.Z.cat.gz (8.8Gb) | W.Z.con.cat.gz (2.5Gb) |
Méthode
La procédure de base est la suivante:
- Genèse des catalogues: application de SExtractor en mode double image à chaque image.
- Masquage des catalogues: masquage des régions où les mesures et les détections astrométriques pourraient être douteuses.
- Fusion: les catalogues de chaque pointage sont amalgamés après masquage et les sources redondantes (qui apparaissent dans plus d'un catalogue) sont supprimées.
Plusieurs autres méthodes ont été envisagées.
Au lieu de produire des catalogues par pointage, puis de les amalgamer, on pourrait appliquer SWarp aux images de chaque champ large pour en tirer une énorme image, puis appliquer SExtractor à cette dernière. Cette méthode aurait pour avantage d'éliminer l'étape "fusion", qui suppose passablement d'écritures. L'inconvénient est que les images de cette taille sont peu maniables. Elles mesureraient jusqu'à 140000 pixels de largeur et auraient un poids de 100Gb. Même si on pouvait (bien que difficilement) appliquer SExtractor à l'image, celle-ci ne pourrait être diffusée sur Internet. L'utilisateur disposerait donc de catalogues ayant pour source une image qu'il ne peut consulter.
Au lieu de créer un catalogue pour chaque filtre, on pourrait bâtir une sorte d'image principale comprenant les flux de chaque bande, par exemple, une image chi carré. On pourrait ensuite appliquer SExtractor en mode double image à l'image principale, qui servirait d'image de détection. La simplicité est l'avantage de cette méthode: elle n'engendre qu'un catalogue. Toutefois, la profondeur est inégale dans les cinq bandes. Ainsi. beaucoup plus de bruit parasite la bande z que les quatre autres. Bien que l'addition des bandes puisse, en théorie, donner une image d'une plus grande profondeur (il y aurait des photons dans toutes les longueurs d'onde), dans la réalité, l'image est plus polluée. Laisser de côté les bandes où le bruit est plus abondant (uz), en revanche, donnerait un catalogue qui ne conviendrait pas à certaines fins.
Au lieu de publier un catalogue par filtre, on pourrait fondre les cinq catalogues en un seul. Les sources communes aux divers catalogues pourraient être identifiées de façon croisée, puis les entrées seraient amalgamées. Encore une fois, l'avantage de cette méthode est la genèse d'un unique catalogue, au lieu de plusieurs. En procédant correctement, on éliminerait les inconvénients de la méthode de l'image principale qui précède. L'astuce, bien sûr, réside dans une identification croisée précise et fiable des sources d'un filtre à l'autre. La chose est aisée pour les sources très lumineuses et bien séparées. Les images MegaPipe sont enregistrées à une très haute précision, ce qui rend l'identification croisée par position passablement précise. Cependant, la qualité et la profondeur de l'image varient avec le filtre; les objets qui correspondent à des sources uniques sur un filtre pouvant correspondre à deux sources sur un autre. Même si l'identification croisée est bien effectuée, le travail d'écriture n'est pas négligeable. Cela dit, cette méthode a donné de bons résultats avec la SDSS, aussi pourrait-on envisager cette solution dans l'avenir.
En résumé, la manière la plus facile d'obtenir un catalogue épuré est la suivante:
- fusionner les pointages au niveau du catalogue plutôt que de l'image;
- ne pas amalgamer les catalogues des différents filtres, mais produire un catalogue par filtre.
À l'ère de la SDSS, il est de moins en moins sensé de garder de simples fichiers ASCII (même s'ils ont leur utilité). C'est pourquoi on a créé une base de données renfermant les catalogues. Une page recherche permet à l'utilisateur de la compulser avec aisance, au lieu d'avoir à procéder à des interrogations en série ou à rédiger son propre script SQL.
Remarque sur la terminologie: études, champs et pointages. La CFHTLS regroupe deux études (le champ profond - Deep - et le champ large - Wide). Chaque étude englobe quatre champs (D1, W3 etc.) et chaque champ inclut un pointage (champ profond) ou plusieurs (champ large) (W1+0+0, W4-1-1, etc.)
Genèse des catalogues individuelles
Les images empilées de la CFHTLS forment la base des catalogues consolidés. En résumé, chaque image MegaCam saisie est traitée avec MegaPipe. Les images font l'objet d'un étalonnage astrométrique et photométrique précis. Elles sont alors décalées (en fonction de l'étalonnage astrométrique) et mises à l'échelle (selon l'étalonnage photométrique), puis empilées avec SWarp. Cela fait, elles sont regroupées par pointage. Les images finales couvrent approximativement un degré carré.
SExtractor a été appliqué aux cinq images de chaque pointage en mode "double image", ce qui permet de détecter les objets dans une image (l'image de référence) et de procéder aux mesures photométriques dans l'autre (l'image de mesure).Ce traitement est appliqué à toutes les combinaisons possibles d'images, si bien que 25 catalogues sont produits par pointage (5 images de référence possibles multiplié par 5 images de mesure possibles). Ces catalogues correspondent aux catalogues individuels. Voici le fichier de configuration de SExtractor.
Masquage des catalogues
Les catalogues ont été masqués pour permettre l'identification des zones où la détection des sources et les mesures photométrique qui s'y rapportent pourraient être compromises. Ces zones comprennent les régions autour des étoiles plus brillantes, les pics de diffraction et de saignement attribuables aux astres les plus lumineux et les traînées des satellites et des météores. Dans certains cas, le schéma de vibration des images saisies ne suffit pas pour obtenir une profondeur uniforme à la grandeur du pointage. Une méthode de détection automatique permet de repérer les étoiles lumineuses ainsi que les pics de diffraction/saignement. À cela s'ajoute un laborieux masquage manuel. Les images ci-dessous illustrent ce qui a été masqué.
Masquage d'une étoile brillante. La position de l'étoile est extraite du Guide Star Catalogue. (Habituellement SExtractor ne peut établir correctement le centre des étoiles très lumineuses.) L'image de la pupille est décalée d'une distance égale à 0,022 fois la distance séparant l'étoile du centre de l'image, vers le centre de l'image par rapport à la position de l'étoile.

Masquage d'un pic de diffraction. Le programme masque les pics de diffraction sur une distance minimale (200 pixels), puis cherche les pics de saignement plus larges (toujours dans l'axe des y). S'il en détecte, le masque est agrandi jusqu'à l'extrémité du saignement.

Masquage de la traînée d'un météore. La trace du météore apparaît sur une seule image saisie. Quand on dispose d'un nombre suffisant d'images saisies, la traînée disparaît au moment de leur combinaison (par application de la valeur médiane), si bien qu'il ne reste qu'un léger bruit résiduel. Cependant, il se peut que le nombre d'images complètes soit insuffisant aux limites du capteur, sur la mosaïque MegaCam, et sur les colonnes défectueuses des images saisies. C'est pourquoi la traînée doit être masquée.

Les masques ont la forme de fichiers de la région ds9. Ils sont exprimés en RA et Dec selon le système de coordonnées J2000.0. Chaque ligne débute par le mot "polygon" que suit une liste de vertex. On peut télécharger les masques de chaque étude sous forme de fichier d'archivage (tarball) au moyen des liens que voici:
- Profond: D.mask.rd.reg.tar.gz
- Large: W.mask.rd.reg.tar.gz
Fusion des catalogues
La dernière étape consiste à fusionner les catalogues. Pour les champs profonds, qui ne se chevauchent pas, on enchaîne simplement les catalogues. Puisque les pointages dans le champ large se chevauchent légèrement, une simple concaténation entraînerait le double comptage de certaines sources.
Quelques méthodes permettent d'éviter cela. Une d'elles consiste à fractionner le champ large avec une grille correspondant aux limites entre les pointages. Les sources détectées à l'intérieur de ces limites sont ajoutées au catalogue; en revanche, on ignore celles situées à l'extérieur en présumant qu'elles seront détectées dans le pointage adjacent. Le hic avec cette méthode est que, s'il existe la moindre incertitude concernant la position des objets situés en bordure d'une limite, ces derniers pourraient être comptés deux fois (une erreur de position pourrait décaler l'objet, lui faisant franchir la limite des deux pointages adjacents) ou être omis complètement (s'ils sont décalés hors des deux pointages consécutivement à l'erreur de position).
L'autre extrême consisterait à regrouper tous les objets de tous les catalogues, puis d'appliquer un filtre afin d'identifier ceux qui ont été doublés. Des sources venant de catalogues différents, mais se trouvant à un court rayon l'une de l'autre seront probablement la même; il suffit alors de supprimer la source redondante. La difficulté avec cette méthode est qu'il existe une probabilité, non négligeable, que deux sources différentes se trouvent vraiment près l'une de l'autre, comme l'illustre la figure ci-dessous.
Probabilité qu'une source ait une voisine dans un rayon donné. F1(θ) correspond à la proportion de sources comptant au moins une source voisine à moins de θ secondes d'arc. Quand l'angle est large, le risque d'avoir une source voisine approche l'unité. Les lignes continues indiquent les résultats respectivement obtenus avec les champs profonds et larges. La proportion mesurée diminue fortement quand θ est inférieur à 1 seconde d'arc. On le doit au fait qu'il devient de plus en plus improbable que les sources proches l'une de l'autre soient correctement séparées. Les lignes hachées montrent la proportion théorique de sources voisines les plus proches, en supposant que les sources sont entièrement réparties au hasard (bref, sans tenir compte du regroupement des galaxies). Les sources dans les champs profonds sont plus susceptibles d'avoir une source voisine, tout simplement parce que les champs profonds englobent les magnitudes plus faibles, ce qui rend les sources plus denses. Dans un champ large, le risque qu'une source voisine se trouve par hasard à moins de 0.5'' est d'environ 1%. Les zones qui se chevauchent entre les pointages larges n'ont habituellement que quelques minutes d'arc de largeur; l'hypothèse qu'on omette 1% de ces sources dans une surface aussi infime doit être rejetée.
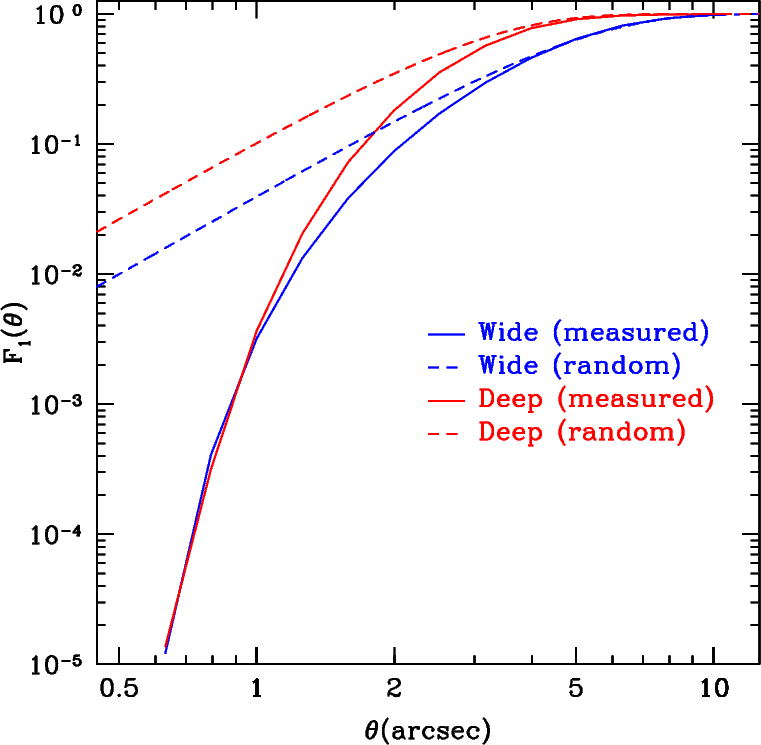
Pour ces raisons, on a retenu une méthode hybride. Les champs larges ont été divisés en grilles tel qu'indiqué plus haut, mais les limites de ces dernières ont été élargies de θoverlap secondes d'arc pour chaque pointage afin qu'elles se chevauchent légèrement. La zone de chevauchement ne mesure maintenant que 2θoverlap secondes d'arc de largeur. La valeur θoverlap=10'' est assez élevée pour satisfaire l'incertitude associée à la position, y compris pour des objets flous d'assez grande taille, mais elle trop faible pour que le risque d'omettre 1% des objets dans cette zone soit acceptable. On élague les sources situées à l'extérieur des limites dans chaque catalogue de pointage. Les catalogues sont combinés après cet élagage. Les objets de catalogues de pointage différents qui se situent à θmatch =0.5'' l'un de l'autre sont réputés être identiques et la deuxième entrée est retranchée.
Cette méthode intègre deux paramètres: θoverlap et θmatch. Changer sensiblement l'un ou l'autre (en les doublant ou en les divisant par deux) n'a eu qu'un effet minime sur les catalogues consolidés: le nombre de sources changerait de quelques centaines, sur un total de 30 millions pour le catalogue.
Des limites ont aussi été appliquées aux bordures des champs. Ces limites se situent au point où la durée d'exposition efficace des images (indiquée par la carte des poids) tombe à la moitié de sa valeur nominale. Ces limites s'appliquent aux pointages à la bordure des champs larges et des champs profonds. Voici la liste des limites appliquées aux pointages.
- Date de modification :