Adjusting Operating System TCP parameters
What is TCP tuning?
Most common traffic over the Internet (e.g. web browsing, downloading files, e-mail) uses Transmission Control Protocol (TCP) over Internet Protocol (IP). TCP is a protocol that encapsulates data so that its delivery over the Internet is reliable (the message you send is the same as the message that gets received), ordered (messages are received in the order they are sent), and connection oriented (to converse, one application must establish a connection to another).
One common concern that most everyone experiences is that of TCP throughput -- the speed at which you can acquire information using TCP -- especially when downloading large files. It is common for people to have a network connection that supports more throughput than they actually experience.
Modern Operating Systems contain software that implements TCP, often transparently to the user, and this software has many parameters that can be set which dramatically influence the performance of TCP. Furthermore, many Operating Systems commonly in use today do not have these settings adjusted to appropriate values to allow a user to take full advantage of a high capacity link, such as a Gigabit Ethernet (GigE) connection to a research institution. The settings which come with these Operating Systems by default may even be insufficient for a home user to take full advantage of a modern broadband connection.
TCP Tuning is the necessary step of adjusting the parameters of an Operating System (the TCP stack) to allow full utilization of a fast network link.
What is TCP tuning not?
TCP tunable parameters limit the theoretical bandwidth between two network locations -- it is possible that the way TCP is configured may be the bottleneck in your transfers. Certainly, if your TCP stack is not appropriately tuned it is unlikely that you will be able to take full advantage of gigabit speeds over the Internet.
However there are numerous other factors which may influence your network performance, such as slow network links, network congestion, application performance limitations, incorrectly configured network equipment, and physical problems with a link. TCP Tuning will not fix any of these problems, and if they exist it is entirely possible that after spending time tuning your TCP stack you will not see any speed increase. TCP tuning is only one part of ensuring that your systems and networks achieve optimum performance.
TCP concepts
This section is not essential for tuning TCP and you may skip it if you wish, but it may help you to have some understanding of how TCP works and what exactly these tunable parameters do.
As described above, one major feature of TCP is reliability. One part of how TCP achieves this reliability is through acknowledgments. When you send out a unit of data (a packet) on a network, it is entirely possible that this packet will be lost due to any number of factors. When an application using TCP (e.g. a web server) sends a piece of data, the recipient of that data must acknowledge that they have received it so that the sender knows it hasn't been lost in transit.
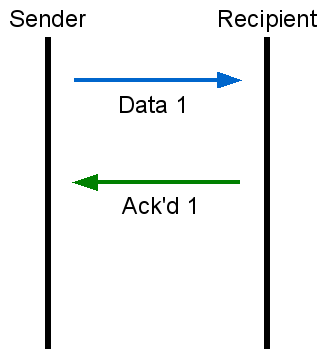 |
| Sender sends data packet #1. Recipient acknowledges the receipt of data packet #1. |
This is much like sending a package to a friend via FedEx and asking them to tell you when they've received it. After all, FedEx might have lost it.
TCP doesn't know how reliable the underlying network is at any point in time. Although it may have previously used the link with some success, any portion of that link may at any time become slow or unreliable, or even cease to exist. This is why when TCP sends data out over a link it will wait for the recipient to acknowledge it before sending any more. If the recipient does not acknowledge the data within a reasonable amount of time, TCP will re-send the data until it meets with success, or gives up and closes the connection.
If you ponder this for a little while, you may realize that this scheme creates an inherent limit in the speed of any data transfer. The network connection between sender and receiver is never instantaneous -- the data will take time to arrive at the recipient, and the recipient's acknowledgment will take time to arrive at the sender. If the sender waits for such an acknowledgment before sending out any more data, this delay will artificially limit data throughput. This artificially imposed limit is irrespective of the link's actual capacity.
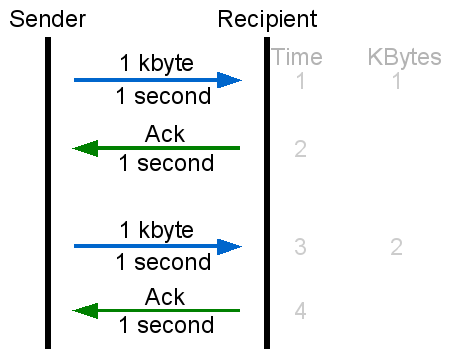 |
| Waiting for acknowledgments limits throughput |
If that isn't immediately clear to you, perhaps an analogy would help. Let's assume that you run a courier service that specializes in transporting packages (data packets). You have a job to ship 5 packages from A (the sender) to B (the recipient). It takes 1 hour of time to drive from A to B over a very large stretch of open highway (an uncongested Gigabit Ethernet research Internet connection). Your plan is to, like TCP, send out your driver with a package, and wait for him to come back saying that he has delivered it.
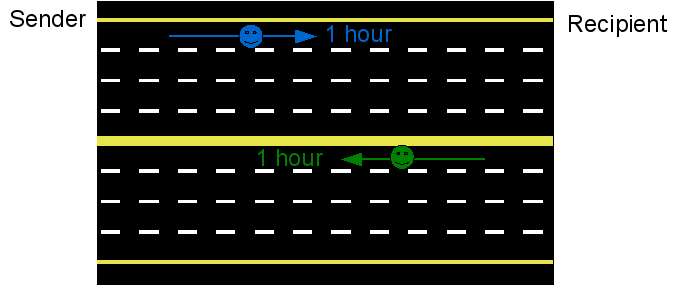 |
| Courier transporting important items over highway |
If you follow this scheme, as you can see, you won't be able to deliver more than one package every two hours, or 0.5 packages per hour. Sounds a lot like bytes per second, doesn't it? You might also notice that the large open highway is looking pretty, well... large and open. Why, a highway like that could easily carry tens of thousands of packages per hour. How could it be that you're only delivering 0.5? Clearly it isn't being used very effectively.
The solution in this scenario is much like the solution TCP uses: send multiple packets (packages) per acknowledgement. The amount of unacknowledged packetized data that can be 'in transit' at any one time is called the TCP window size.
The way in which this was implemented in the first TCP specification had a few problems: The window size value was 16-bit and thus limited to 64 kilobytes of data, imposing a maximum throughput. For example on a Gigabit Ethernet link with a 20 millisecond delay, a 64 kbyte window would only let you transfer 3.125 megabytes per second. The situation gets worse with higher latencies -- the same link with a 100 ms delay would only let you transfer 640 kilobytes per second. Additionally the sender of the data was only able to discern one lost packet per round trip time, due to the nature of the acknowledgement message.
These problems were solved by the RFC 1323 (Timestamps, Window Scaling) and RFC 2018 (Selective Acknowledgement) extensions to TCP. Window scaling is the most important option, as it allows window sizes over 64 kbyte to be used. Selective acknowledgement (SACK) allows the receiving end to acknowledge data in a way which minimizes the number of retransmissions necessary, and the timestamping option applies a time stamp to each packet, allowing hosts to determine the path delay.
The goal of TCP tuning is to turn on modern TCP extensions, if they are not already on by default, and set the window size to a value appropriate for the network path.
The general formula for TCP throughput relates the window size, link speed, and link latency in the Bandwidth Delay Product (BDP). This states that the product of bandwidth and delay is the window size; (bandwidth in bytes/second) * (delay in seconds) = (window size in bytes). To achieve an optimum window size for a given path, the path bandwidth must be known, and is constricted by the lowest link speed in the path. For research network connections a safe assumption is either 100 mbit/s or 1000 mbit/s, depending on campus and department connectivity.
Setting a window size that is too large has little negative effect except to waste memory. Setting one that is too small will serve to limit throughput. TCP also has separate window sizes for transmitting and receiving, but this is beyond the scope of the document. For the purposes of downloading data, it is only important to tune the receive window (RWIN) size.
Operating System specific tuning methods
Linux
The tunable TCP parameters for the Linux Operating System can be found in the tcp(7) manual page. The important values are sysctl(8) variables which can be accessed, as the root user, using the 'sysctl' utility or /proc filesystem. The values important for tuning TCP receive window sizes are detailed below:
- net.core.rmem_default controls the default socket receive buffer size, in bytes.
- net.core.rmem_max controls the maximum socket receive buffer size, in bytes.
- net.ipv4.tcp_window_scaling turns TCP window scaling on or off.
- net.ipv4.tcp_sack turns Selective Acknowledgements on or off.
- net.ipv4.tcp_timestamps turns timestamps on or off.
- net.ipv4.tcp_mem adjusts TCP stack memory utilization, in the format
low pressure high. Low is the number of memory pages (not bytes) under which the TCP stack will not attempt to reduce memory utilization. Pressure is the number of memory pages over which the stack will attempt to reduce memory utilization. High is the maximum number of memory pages that the TCP stack is allowed to use. - net.ipv4.tcp_rmem adjusts the minimum, default, and maximum TCP receive window sizes, in bytes.
To begin modifying the Linux Kernel TCP parameters you will need root access to your machine. This can usually be achieved through a facility like su(1) or sudo(8). Once you are acting as the root user, use your favorite editor to open /etc/sysctl.conf. Insert the following lines at the end of sysctl.conf. If these values were previously defined in sysctl.conf you should make sure to remove the older definitions.
net.core.rmem_default = 1048576
net.core.rmem_max = <receive window size>
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_sack = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_rmem = 4096 1048576 <receive window size>
Substitute <receive window size> for the window size, in bytes, provided during your test analysis with the CADC network analyst. Alternatively you can calculate one for yourself using the bandwidth delay product of your desired network path, as detailed above.
Check that the 'pressure' (middle number) value of net.ipv4.tcp_mem is larger than <receive window size> divided by your system page size. If you do not know your system page size, you can check it by running getconf PAGESIZE in a shell; this value is usually 4096 (4kbyte) on 32-bit Intel platforms.
After editing sysctl.conf, you can make these changes active by running sysctl -p /etc/sysctl.conf or rebooting.
This information was verified on Linux Kernel version 2.6.27, under OpenSUSE.
FreeBSD
The tunable TCP parameters for the FreeBSD Operating System are sysctl(8) variables which can be accessed, as the root user, using the 'sysctl' utility. Information on some of these tunable parameters can be found in the FreeBSD Handbook. The values important for tuning TCP receive window sizes are detailed below:
- kern.ipc.nmbclusters is the amount of memory allocated to the networking stack, in 2 kbyte clusters, and must be set at boot time.
- kern.ipc.maxsockbuf is the maximum combined socket buffer size, in bytes.
- net.inet.tcp.recvspace is the default socket receive buffer size, in bytes.
- net.inet.tcp.recvbuf_max is the maximum socket receive buffer size, for autotuning, in bytes.
- net.inet.tcp.hostcache.expire governs expiry of cached congestion information.
- net.inet.tcp.inflight.enable turns inflight BDP estimation on or off.
- net.inet.tcp.rfc1323 turns TCP window scaling on or off.
- net.inet.tcp.sack.enable turns Selective Acknowledgements on or off.
- net.inet.tcp.recvbuf_auto turns receive window autotuning on or off.
- net.inet.tcp.recvbuf_inc governs the receive window autotuning step size.
To begin modifying FreeBSD TCP parameters you will need root access to your machine. This can usually be achieved through a facility like su(1). Once you are acting as the root user, use your favorite editor to open /etc/sysctl.conf. Insert the following lines at the end of sysctl.conf. If these values were previously defined in sysctl.conf you should make sure to remove the older definitions.
kern.ipc.maxsockbuf=<8 * receive window size>
net.inet.tcp.rfc1323=1
net.inet.tcp.sack.enable=1
net.inet.tcp.recvspace=<receive window size>
net.inet.tcp.recvbuf_max=<receive window size>
net.inet.tcp.hostcache.expire=1
net.inet.tcp.inflight.enable=0
net.inet.tcp.recvbuf_auto=1
net.inet.tcp.recvbuf_inc=524288
Substitute <receive window size> for the window size, in bytes, provided during your test analysis with the CADC network analyst. Alternatively you can calculate one for yourself using the bandwidth delay product of your desired network path, as detailed above. For kern.ipc.maxsockbuf, note that you will have to multiply the window size by eight.
Next, you must alter the value of kern.ipc.maxsockbuf by, as root, using an editor to open /boot/loader.conf. As with /etc/sysctl.conf, insert the new lines at the end and remove older definitions of the values.
kern.ipc.nmbclusters=<(receive window size * 10) / 2048>
Note that for kern.ipc.maxsockbuf the window size is multiplied by 10, then divided by 2048 (to turn it into the number of 2 kbyte clusters necessary).
Since you have modified kern.ipc.maxsockbuf, which must be set at boot time, rebooting the machine is the easiest way to implement these changes.
This information was verified on FreeBSD 7.2.
OS X
The tunable TCP parameters for the Apple OS X Operating System are sysctl(8) variables which can be accessed, as the root user, using the 'sysctl' utility. The values important for tuning TCP receive window sizes are detailed below:
- kern.ipc.nmbclusters is the amount of memory allocated to the networking stack, in 2 kbyte clusters, and must be set at boot time. Already set to an acceptable default on most OS X systems.
- kern.ipc.maxsockbuf is the maximum combined socket buffer size, in bytes.
- net.inet.tcp.rfc1323 turns TCP window scaling on or off.
- net.inet.tcp.sack turns Selective Acknowledgements on or off.
- net.inet.tcp.recvspace is the default socket receive buffer size, in bytes.
To begin modifying OS X TCP parameters you will need root access to your machine. This can usually be achieved through a facility like sudo(8). To use sudo, open a terminal and run sudo <command> where <command> is the command you want to run. This can be a text editor or sh to get a root shell. Once you are acting as the root user, use your favorite editor to open /etc/sysctl.conf. Insert the following lines at the end of sysctl.conf. If these values were previously defined in sysctl.conf you should make sure to remove the older definitions.
kern.ipc.maxsockbuf=<8 * receive window size>
net.inet.tcp.rfc1323=1
net.inet.tcp.sack=1
net.inet.tcp.recvspace=<receive window size>
Substitute <receive window size> for the window size, in bytes, provided during your test analysis with the CADC network analyst. Alternatively you can calculate one for yourself using the bandwidth delay product of your desired network path, as detailed above. For kern.ipc.maxsockbuf, note that you will have to multiply the window size by eight.
The easiest way of implementing the changes you have made is to reboot the machine.
This information was verified on OS X 10.5.8.
Solaris
The tunable TCP parameters for the Solaris Operating System are ndd(1M) variables which can be accessed, as the root user, using the 'ndd' utility. The values important for tuning TCP receive window sizes are detailed below:
- tcp_recv_hiwat is the default TCP receive window size.
- tcp_max_buf is the maximum TCP receive window and socket buffer size.
- tcp_wscale_always tells the Operating System whether or not to always use TCP window scaling.
- tcp_tstamp_if_wscale turns TCP timestamps on or off.
- tcp_sack_permitted turns Selective Acknowledgements on or off.
To begin modifying the Operating System TCP parameters you will need root access to your machine. This can usually be achieved through a facility like su(1M). Once you are acting as the root user, use your favorite editor to open /etc/system. Insert the following lines at the end of system. If these values were previously defined in system you should make sure to remove the older definitions.
set ndd:tcp_recv_hiwat=1048576
set ndd:tcp_max_buf=<receive window size>
set ndd:tcp_wscale_always=1
set ndd:tcp_tstamp_if_wscale=1
set ndd:tcp_sack_permitted=2
Substitute <receive window size> for the window size, in bytes, provided during your test analysis with the CADC network analyst. Alternatively you can calculate one for yourself using the bandwidth delay product of your desired network path, as detailed above.
To implement these changes you can either choose to reboot the machine, or use the 'ndd' utility to set each variable directly on the running system. For example:
ndd -set /dev/tcp tcp_recv_hiwat 1048576
ndd -set /dev/tcp tcp_max_buf <receive window size>
[...]
This information was verified on Solaris 10 - 10/09.